

4 ways to manage Kubernetes resources
Kubectl is the new ssh
When I started my adventure with linux systems the first tool I had to get to know was ssh. Oh man, what a wonderful and powerful piece of software it is! You can not only log in to your servers, copy files, but also create vpns, omit firewalls with SOCKS proxy and port-forwarding rules, and many more. With Kubernetes, however, this tool is used mostly for node maintenance provided that you still need to manage them and you haven’t switched to CoreOS or another variant of the immutable node type. For any other cases, you use kubectl which is the new ssh. If you don’t use API calls directly then you probably use it in some form and you feed it with plenty of yaml files. Let’s face it - this is how managing Kubernetes environment looks like nowadays. You create those beautiful, lengthy text files with the definitions of the resources you wish to be created by Kubernetes and then magic happens and you’re the hero of the day. Unless you want to create not one but tens or hundreds of them with different configurations. And that’s when things get complicated.
Simplicity vs. flexibility
For basic scenarios, simple yaml files can be sufficient. However, with the growth of your environment, the number of resources and configurations grows. You may start noticing how much more time it takes to create a new instance of your app, reconfigure the ones that are running already or share it with the community or with your customers wishing to customize it to their needs. Currently, I find the following ways to be the most commonly used:
- Plain yaml files
- Kustomize
- Helm Charts
- Operators
They all can be used to manage your resources and they also are different in many ways. One of the distinguishing factors is complexity which also implies much effort to learn, use and maintain a particular method. On the other hand, it might pay off in the long run when you really want to create complex configurations. You can observe this relationship in the following diagram:
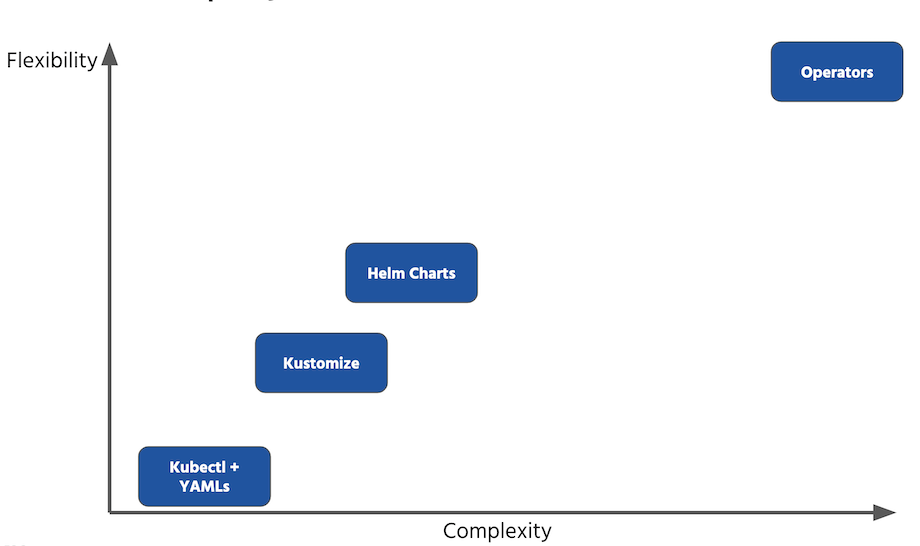
So there’s a trade-off between how much flexibility you want to have versus how simple it can be. For some simplicity can win and for some, it’s just not enough. Let’s have a closer look at these four ways and see in which cases they can fit best.
1. Keep it simple with plain yamls
I’ve always told people attending my courses that by learning Kubernetes they become yaml programmers. It might sound silly, but in reality, the basic usage of Kubernetes comes down to writing definitions of some objects in plain yaml. Of course, you have to know two things - the first is what you want to create, and the second is the knowledge on Kubernetes API which is the foundations of these yaml files.
After you’ve learned how to write yaml files you can just use kubectl to send it to Kubernetes and your job is done. No parameters, no templates, not figuring out how to change it in a fancy way. If you want to create an additional instance of your application or the whole environment you just copy and paste. Of course, there will be some duplication here but it’s the price you pay for simplicity. And besides, for a couple of instances it’s not a big deal and most of the organizations probably can live with this imperfect solution, at least at the beginning of their journey when they are not as big as they wish to be.
When to use:
- For projects with less than 4 configurations/instances of their apps or environments
- For small startups
- For bigger companies starting their first Kubernetes projects (e.g. as a part of PoC)
- For individuals learning Kubernetes API
When to avoid:
- organizations and projects releasing their products or services for Kubernetes environments
- in projects where each instance varies significantly and requires a lot of adjustments
2. Customize a bit with Kustomize
Kustomize is a project that is one of Kubernetes official SIG groups. It has the concept of inheritance based Kubernetes resources defined in.. yaml files. That’s right - you cannot escape from them! This time, however, with Kustomize you can apply any changes you want to your already existing set of resources. To put it simply Kustomize can be treated as a Kubernetes-specific patch tool. It lets you override all the parts of yaml files with additional features, including the following:
- Changing repositories, names, and tags for container images
- Generating ConfigMap objects directly from files and generate hashes ensuring that Deployment will trigger a new rollout when they change
- Using kustomize cli to modify configurations on the fly (useful in CI/CD pipelines)
From version 1.14 it is built-in to kubectl binary which makes it easy to start with. Unfortunately, new features are added much faster in standalone kustomize project and its release cycle doesn’t sync up with the official releases of kubectl binaries. Thus, I highly recommend using its standalone version rather than kubectl’s built-in functionality.
According to its creators, it encourages you to use Kubernetes API directly without creating another artificial abstraction layer.
When to use:
- For projects with less than 10 configurations/instances that don’t require too many parameters
- For startups starting to grow, but still using Kubernetes internally (i.e. without the need to publish manifests as a part of their products)
- For anyone who knows Kubernetes API and feels comfortable with using it directly
When to avoid:
- If your environments or instances vary up to between 30-50%, because you’ll just rewrite most of your manifests by adding patches
- In the same cases as with plain yamls
3. Powerful Helm Charts for advanced
If you haven’t seen Helm Hub then I recommend you to do it and look for your favorite software, especially if it’s a popular open-source project, and I’m pretty sure it’s there. With the release of Helm 3 most of its flaws have been fixed. Actually the biggest one was the Tiller component that is no longer required which makes it really great tool for your deployments. For OpenShift users that could also be a great relief since its templating system is just too simple (I’m trying to avoid word terrible but it is).
Most people who have started using Helm for deploying these ready services often start writing their own Charts for applications and almost everything they deploy on Kubernetes. It might be a good idea for really complex configurations but in most cases, it’s just overkill. In cases when you don’t publish your Charts to some registry (and soon even to container registries) and just use them for their templating feature (with Helm 3 it is finally possible without downloading Chart’s source code), you might be better of with Kustomize.
For advanced scenarios, however, Helm is the way to go. It can be this single tool that you use to release your applications for other teams to deploy to their environments. And so can your customers who can use a single command - literally just helm upgrade YOURCHART - to deploy a newer version of your app. All you need to do in order to achieve this simplicity is “just”:
- write Chart templates in a way that would handle all these cases and configuration variants
- create and maintain the whole release process with CI/CD pipeline, testing, and publishing
Many examples on Helm Hub shows how complex software can be packed in a Chart to make installation a trivial process and customization much more accessible, especially for end-users who don’t want to get into much details. I myself use many Helm Charts to install software and consider it as one of the most important projects in Kubernetes ecosystem.
When to use:
- For big projects with more than 10 configurations/instances that have many variants and parameters
- For projects that are published on the Internet to make them easy to install
When to avoid:
- If your applications are not that complex and you don’t need to publish them anywhere
- If you don’t plan to maintain CI/CD for the release process cause maintaining Charts without pipelines is just time-consuming
- If you don’t know Kubernetes API in-depth yet
4. Automated bots (operators) at your service
Now, the final one, most sophisticated, and for some superfluous. In fact, it’s a design pattern proposed by CoreOS (now Red Hat) that just leverages Kubernetes features like Custom Resource Definition and custom logic embedded in software running directly on Kubernetes and leveraging its internal API called controllers. It is widely used in the OpenShift ecosystem and it’s been promoted by Red Hat since the release of OpenShift 4, as the best way to create services on OpenShift. They even provide an operator for customizing OpenShift’s web interface. That’s what I call an abstraction layer! Everything is controlled there with yaml handled by dozens of custom operators, because the whole logic is embedded there.
To put it simply what is operator I would say that operator is an equivalent of cloud service like Amazon RDS, GCP Cloud Pub/Sub or Azure Cosmos DB. You build an operator to provide a consistent, simple way to install and maintain (including upgrades) your application in ”-as-a-Service” way on any Kubernetes platform using its native API. It does not only provide the highest level of automation, but also allows for including complex logic such as built-in monitoring, seamless upgrades, self-healing and autoscaling. Once again - all you need to do is provide a definition in yaml format and the rest will be taken care of by the operator.
“It looks awesome!” one can say. Many think it should and will be a preferred way of delivering applications. I cannot agree with that statement. I think if you’re a software vendor providing your application to hundreds of customers (even internally) then this is the way to go. Otherwise, it can be too complex and time consuming to write operators. Especially if you want to follow best practices, use Golang and provide an easy upgrade path (and it can get tricky).
I found the following projects to be very helpful in developing and maintaining Operators:
- kubebuilder - one of the first operator frameworks for Go developers, the most poweful and the most complex one
- kopf - framework for developing operators in python KUDO - write operators in a declarative way
- operator-sdk - framework from
CoreOSRed Hat for writing operators in Go and Ansible - operator-lifecycle - a must have for anyone interested in getting serious with operators and their lifrecycle (installation, maintenance, upgrades)
When to use:
- If you need to create your own service (e.g. YourProduct-as-a-Service) available on Kubernetes
- If you plan to add additional features to your service (e.g. monitoring, autoscaling, autohealing, analytics)
- If you’re a software vendor providing your software for Kubernetes platforms
- If you want to develop software installed on OpenShift and be a part of its ecosystem (e.g. publish your software on their ”app marketplace” - operatorhub.io)
When to avoid:
- For simple applications
- For other applications when Helm Chart with some semi-complex templates will do
- When no extra automation is needed or it can be acomplished with simple configuration of the existing components
Conclusion
Each of these methods and tools I have described are for organizations at different point of their journey with Kubernetes. For standard use-cases simple yamls may be sufficient and with more applications Kustomize can be great enhancement of this approach. When things get serious and applications get more complex, Helm Chart presents a perfect balance between complexity and flexibility. I can recommend Operators for vendors delivering their applications in Kubernetes in a similar way to cloud services, and definitely for those who plan to provide it for enterprise customers using OpenShift.




Leave a comment