

Maintaining big Kubernetes environments with factories
People are fascinated by containers, Kubernetes and cloud native approach for different reasons. It could be enhanced security, real portability, greater extensibility or more resilience. For me personally, and for organizations delivering software products for their customers, there is one reason that is far more important - it’s more speed they can gain. That leads straight to decreased Time To Market, so highly appreciated and coveted by the business people, and even more job satisfaction for guys building application and platforms for them.
It starts with code
So how to speed it up? By leveraging this new technology and all the goodies that come with it. The real game-changer here is the way you can manage your platform, environments, and applications that run there. With Kubernetes based platforms you do it in a declarative manner which means you define your desired state and not particular steps leading to the implementation of it (like it’s done in imperative systems). That opens up a way to manage the whole system with code. Your primary job is to define your system state and let Kubernetes do its magic. You probably want to keep it in files in a versioned git repository (or repositories) and this article shows how you can build your platform by efficiently splitting up the code to multiple repositories.
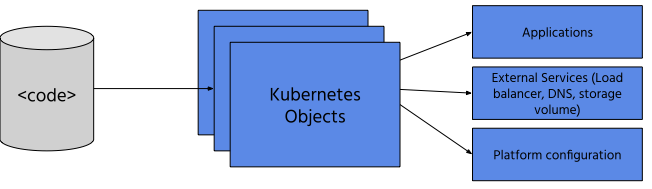
Areas to manage
Since we can manage all the things from the code we could distinguish a few areas to delegate control over a code to different teams.
Let’s consider these three areas:
1. Platform
This is a part where all platform and cluster-wide configuration are defined. It affects all environments and their security. It can also include configuration for multiple clusters (e.g. when using OpenShift’s Machine Operator or Cluster API to install and manage clusters).
Examples of objects kept here:
- LimitRange, ResourceQuota
- NetworkPolicy, EgressNetworkPolicy
- ClusterRole, ClusterRoleBinding
- PersistentVolume - static pool
- MachineSet, Machine, MachineHealthCheck, Cluster
2. Environments (namespaces) management
Here we define how particular namespaces should be configured to run applications or services and at the same time keep it secure and under control.
Examples of objects kept here:
- ConfigMap, Secret
- Role, RoleBinding
3. CI/CD system
All other configuration that is specific to an application. Also, the pipeline definition is kept here with the details on how to build an application artifact from code, put it in a container image and push it to a container registry.
Examples of objects kept here:
- Jenkinsfile
- Jenkins shared library
- Tekton objects: Pipeline, PipelineRun, Task, ClusterTask, TaskRun, PipelineResource
- BuildConfig
- Deployment, Ingress, Service
- Helm Charts
- Kustomize overlays
Note that environment-specific configuration is kept elsewhere.
Factories
Our goal here is simple - leverage containers and Kubernetes features to quickly deliver applications to production environments and keep it all as code. To do so we can delegate management of particular areas to special entities - let’s call them factories. We can have two types of factories:
- Factory Building Environments (FBE) - responsible for maintaining objects from area 1 (platform).
- Factory Building Applications (FBA) - responsible for maintaining objects from area 2 (environments) and area 3 (CI/CD)
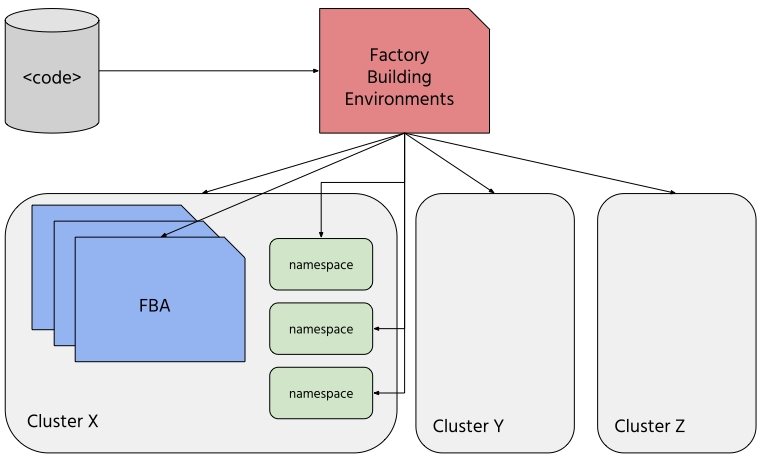
Factory Building Environments
First is a Factory Building Environments. In general, a single factory of this type is sufficient because it can maintain multiple environments and multiple clusters.
It exists for the following main reasons:
- To delegate control over critical objects (especially security-related) to a team of people responsible for platform stability and security
- To keep track of changes and protect global configuration that affects all the shared services and applications running on a cluster (or clusters)
- To ease management of multiple clusters and dozens (or even hundreds) of namespaces
Main tasks
So what kind of tasks does this factory is responsible for? Here are the most important ones.
Build and maintain shared images
There are a couple of container images that are used by many services inside your cluster and have a critical impact on platform security or stability. This could be in particular:
- a modified Fluentd container image
- a base image for all your java (or other types) applications with your custom CA added to a PKI configuration on a system level
- similarily - a custom s2i (Source to Image) builder
- a customized Jenkins Image with a predefined list of plugins and even seed jobs
Apply security and global configuration
This is actually the biggest and most important task of this factory. It should read a dedicated repository where all the files are kept and apply it to either at a cluster level or for a particular set of environments (namespaces).
Provide credentials
In some cases, this should also be a place where some credentials are configured in environments - for example, database credentials that shouldn’t be visible by developers or stored in an application repository.
Build other factories
Finally, this factory also builds other factories (FBA). This task includes creating new namespaces, maintaining their configuration and deploying required objects forming a new factory.
How to implement
FBE is just a concept that can be implemented in many ways. Here’s a list of possible solutions:
- The simplest case - a dedicated repository with restricted access, code review policy, and manual provisioning process.
- The previous solution can be extended with a proper hook attached to an event of merge of a pull request that will apply all changes automatically.
- As a part of git integration there can be a dedicated job on CI/CD server (e.g. Jenkins) that tracks a particular branch of the repo and also applies it automatically or on-demand.
- The last solution is the most advanced and also follows the best practices of cloud native approach. It is a dedicated operator that tracks the repository and applies it from inside a container. There could be different Custom Resources that would be responsible for different parts of configurations (e.g. configuration of namespace, global security settings of a cluster, etc.).
Factory Building Applications
The second type of factory is a factory building applications. It is designed to deliver applications to end-users to prod environments. It addresses the following challenges of delivery and deployment processes:
- Brings more autonomy for development teams who can use a dedicated set of namespaces for their delivery process
- Creates a safe place for experiments with preview environments created on-demand
- Ease the configuration process by reducing duplication of config files and providing default settings shared by applications and environments
- Enables grouping of applications/microservices under a single, manageable group of environments with shared settings and an aggregated view on deployment pipelines runs
- Separates configuration of Kubernetes objects from a global configuration (maintained by FBE) and application code to keep track of changes
Main tasks
Let’s have a look at the main tasks of this factory.
Build and deploy applications
The most important job is to build applications from a code, perform tests, put them in a container image and publish. When a new container image is ready it can be deployed to multiple environments that are managed by this factory. It is essentially the description of CI/CD tasks that are implemented here for a set of applications.
Provide common configuration for application and services
This factory should provide an easy way of creating a new environment for an application with a set of config files defining required resources (see examples of objects in area 2 and 3).
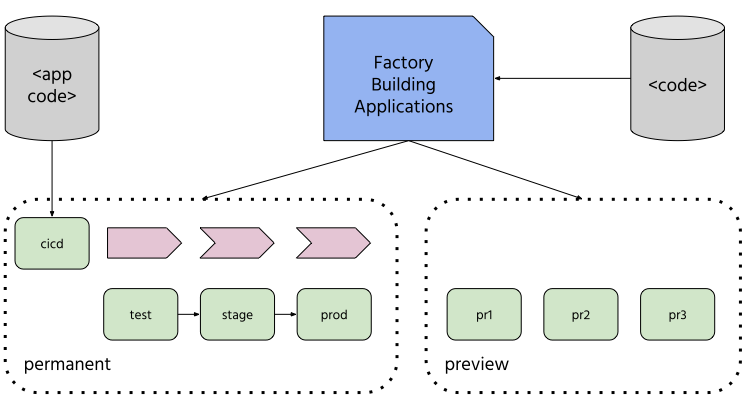
Namespace management
FBA manages two types of environments (namespaces):
- permanent environments - they are a part of CI/CD pipeline for a set of applications (or a single app) and their services
- preview environments - these are environments that are not a part of CI/CD pipeline but are created on-demand and used for different purposes (e.g. feature branch tests, performance tests, custom scenario tests, etc.)
It creates multiple preview environments and destroys them if they are no longer needed. For permanent environments, it ensures that they have a proper configuration but never deletes them (they are special and protected).
How to implement
Here are some implementation tips and more technical details.
-
A factory can be created to maintain environments and CI/CD pipeline for a single application, however, often many applications are either developed by a single team or are a part of a single business domain and thus it is convenient to keep all the environments and processes around deployment in a single place.
-
A factory consists of multiple namespaces, for example:
FN-cicd- namespace where all build-related and delivery activities take place (FNcould be a factory name or some other prefix shared by namespaces managed by it)FN-test, FN-stage, FN-prod- permanent environments- various number of preview environments
-
Main tasks can be implemented by Jenkins running inside FN-cicd namespace and can be defined either by independent Jenkinsfiles or with jobs defined in a shared library configured on a Jenkins instance.
In OpenShift it’s even easier, as you can use BuildConfig objects of Pipeline type which will create proper jobs inside a Jenkins instance. -
A dedicated operator seems to be again the best solution. It could be implemented as the same operator which maintains FBE with a set of Custom Resources for managing namespaces, pipelines and so on.
Summary
A couple of years ago, before docker and containers, I was a huge fan of Infrastructure as Code. With Kubernetes, operators, and thanks to its declarative nature, it is now possible to manage all the aspects of application building process, deployment, management of environments it would run in and even whole clusters deployed across multiple datacenters or clouds. Now it’s becoming increasingly important how are you handling the management of the code responsible for maintaining it. The idea of using multiple factories is helpful for organizations with many teams and applications and allows easy scaling of both and keeping it manageable at the same time.




Leave a comment