

Three levels of highly available apps on Kubernetes
Beautiful but useless systems
Hundreds of applications, thousands of users and millions of requests - that is often a landscape of modern IT environment. Still problems are the same. One of the most important is how to achieve high availability of your service. After all you’ve been crafting all those microservices with beautiful architecture, bounded contexts and newest frameworks so that the world could admire and use it. That won’t happen if you don’t provide proper level of availability. Even the most brilliant and sophisticated system is useless when it’s rarely available.
In this article I’m focusing on application side and how to achieve the best results with proper approach, configuration and processes. Kubernetes itself has a pretty simple architecture and control plane (master servers) are easy to set up in HA cluster. Although there are interesting topics in it as well I’m not going to elaborate on them now.
The best investment
You should be aware that the less your service is available the more problems you have. In the first place you lose money when your paying customers cannot use it. However this is not the biggest issue here. Eventually you are able to bring it back to live, but every time your service fails it decreases your credibility. Customers and business partners start to perceive your company as less reliable and eventually you may lose not only your current business, but also future opportunities. And so one of the best investment decisions is the one that would increase availability of your service. That’s where containers come to rescue with their built-in capabilities making high availability as easy as never before.
Cloud Native approach to high availability
Kubernetes is a project founded by Google and is based on their experiences of running millions containers with thousands applications for many years. It’s for sure a good example and a reliable source of best practices that we can all apply today in our environments. We must however embrace the new way of delivering applications - perform it in a Cloud Native way. There are a couple of elements of this approach that are essential to application resilience. The most important one is ephemerality.
Ephemeral components of container environment
Containers are ephemeral by design and this definitely makes things easier. You cannot restart them, but only start new ones from immutable container image. Since it’s working that way by design no one should care if there was some data written by particular container instance. All data and configuration must be decoupled from container. Kubernetes keeps configuration in ConfigMap and Secret objects while data is kept on PersistentVolumes. So whenever container crashes for some reason, a new one is created and all data is delivered to it regardless of the node it’s been launched on. And that’s where it gets even more interesting. When using containers with Kubernetes all non-master nodes are treated as ephemeral too! You can remove, add new ones or replace in case of any failures without all those tricky and often proprietary cluster solutions.
Three levels
With containers running on Kubernetes we can distinguish three levels of high availability. They are available for every applications running inside a container and in most cases you can rely on default configuration which provides a reasonable level reliability.
Level 1 - Pod
Application in Kubernetes runs inside Pods which are composed of one or more containers and they are nothing more than just a special processes. These processes can sometimes crash for various reasons that are just hard to predict. Sometimes they crash because of badly written software, other times it’s just unexplainable and hard to trace event that occurs at random times.
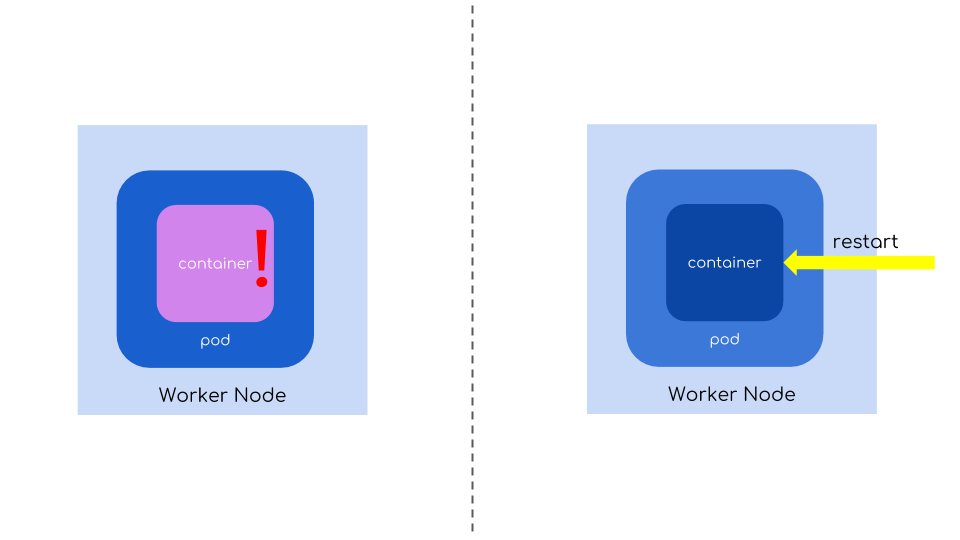
By default these processes are restarted automatically fixing those intermittent problems for you.
Kubernetes also assumes that when a process is running it means your app is working properly. However often it’s not true and while process may exists your app could actually send a malformed replies to users or even don’t send any at all. That’s why there’s a livenessProbe that can be defined for each container to not only restart them in case of crash, but also perform periodic active checks with one of these three methods:
- ExecAction - execute script inside a container
- TCPSocketAction - check whether a TCP port is open
- HTTPGetAction - check an HTTP code returned by GET method performed on specified URL - the best choice for web applications
By using them your container will be protected from not only unexpected crashes, but also from upcoming ones with proactive restarts based on results of these checks.
So even on this basic level Kubernetes keeps your containers running and with a little effort you can tune it to get even more reliability.
How to increase availability on a pod level
To set your availability levels higher you should consider the following:
-
Define a livenessProbe for each container. Use proper method. Avoid ExecAction when your container can process HTTP requests. Set proper initialDelaySeconds parameter to give your app some time to initialize (especially for ones based on JVM like Spring Boot - they are slow to start their HTTP endpoints)
-
For web apps use HTTPGetAction and make sure your app can inform Kubernetes whether it works only using http code (this type doesn’t check content of the reply). It is recommended to use standard url for all apps e.g.
/healthz. Make sure that you check only state of your apps and not underlying services such as database. -
To decrease time needed for recovery you should also make your container images small so that on cold start (i.e. node starts a pod from an app image for the first time) to minimize a time required to download the image. It is mostly visible in big environments where network bandwidth is a precious resource and there are hundreds of different containers running - then every additional 10MB of container image size can make a huge difference.
Level 2 - Node
Second level of resilience is assured by multi-node architecture and scalability features of Kubernetes. Let’s start with the simplest scenario where an app is running as a single instance in one pod. When a node that was running it crashes, the new pod is created by Kubernetes on other, available and healthy node that meets its requirements (cpu/mem reservations, taints, affinities etc.). In that way Kubernetes recovers from node crashes even for those singe-instance apps. Of course this is a rare case since most workload are running in multiple instances spread across multiple nodes. With Kubernetes features such as affinity settings you can request scheduler to assign a node for each application in a way that would minimize impact of node crash - only a small number of them would have to be recreated.
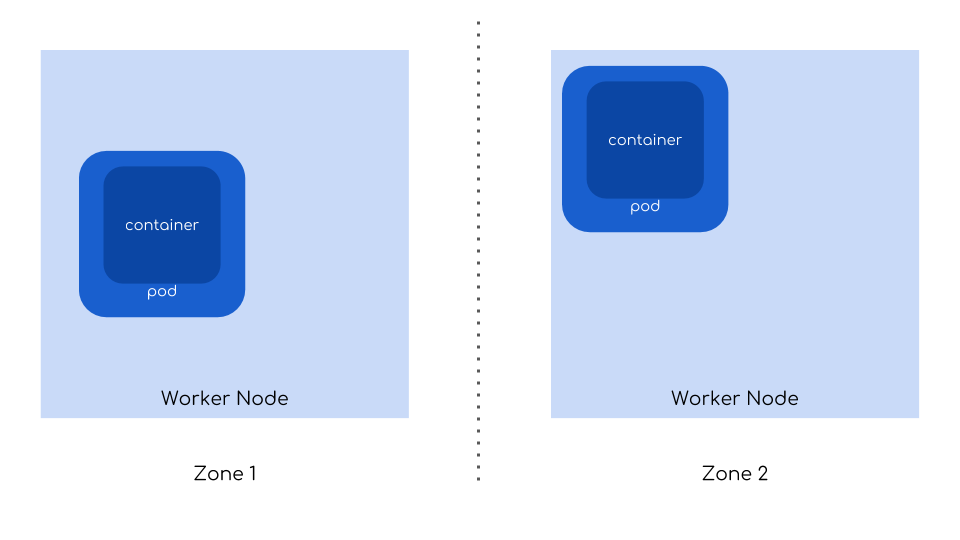
On cloud environments you can leverage multiple availability zones to make your cluster resilient even to a failure of the whole data center. What is more interesting is that by default Kubernetes scheduler will try to spread your pods across available those failure domains. All you need to do is to make sure you place your nodes in multiple zones.
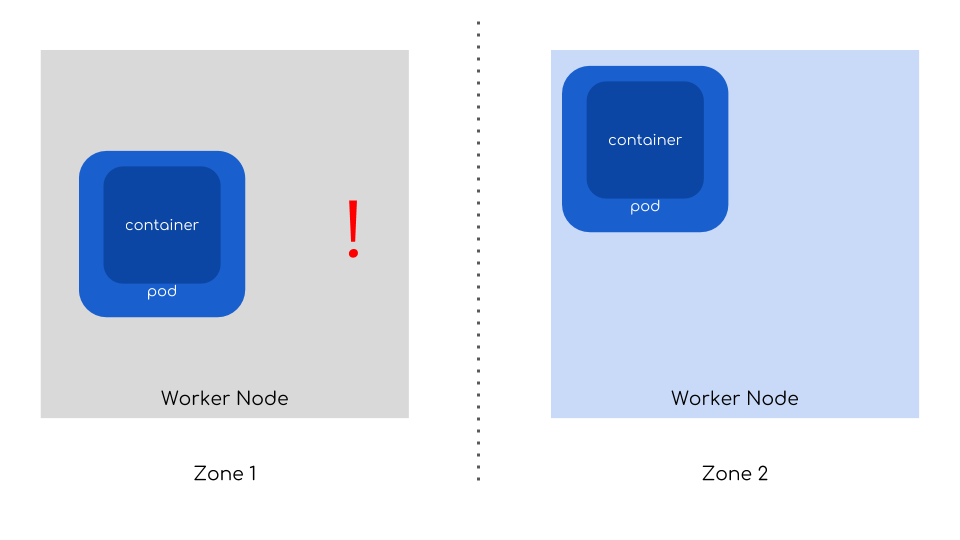
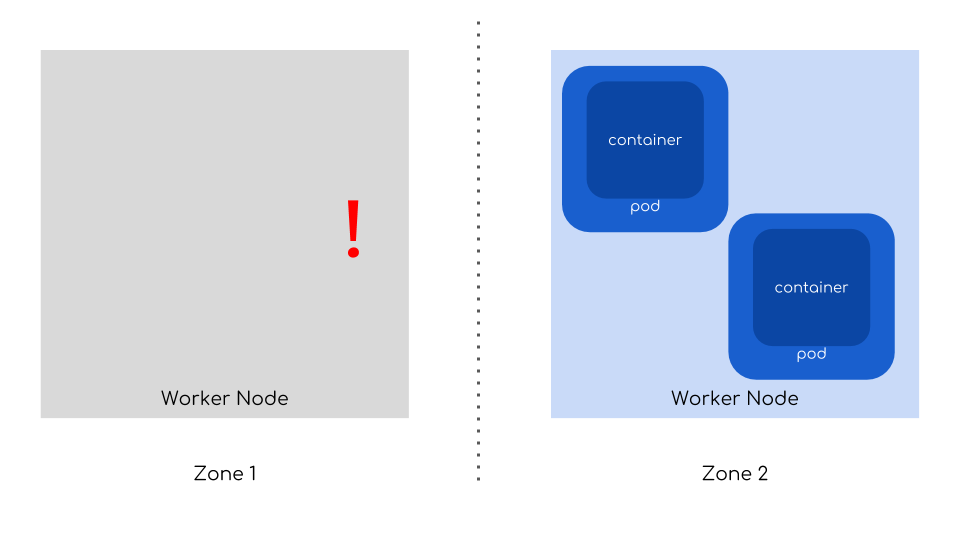
And that’s how you can mitigate crashes of a node, multiple nodes or even whole data centers!
How to increase availability on a node level
These are recommended practices you should apply to your config on a Node level:
-
For non-cloud environments you can leverage automatic distribution of pods across your failure domains by assigning proper labels to nodes - use
failure-domain.beta.kubernetes.io/zoneas key and arbitrary, unique keys for each failure domain. -
Never launch your app directly from a Pod - it won’t survive a crash of a node. Even for single pod applications use ReplicaSet or Deployment objects, as they manage pods across whole cluster and maintain specified number of instances (even if it’s only one).
-
Use affinity configuration with custom rules to spread your pods based on your environments architecture, especially when you run Kubernetes on non-cloud environments. For example you could define multiple failure domains based on server type, rack, server room and data center.
Level 3 - Multiple Clusters
Last level can add even more nines to your availability SLO. You can achieve it by deploying your apps on multiple clusters. It is quite easy with Kubernetes since a recipe for your app is simple:
running app = container image (1) + configuration (2) + objects definition (3) + data (4)
(1) is kept in container registries that can be replicated as a part of CI/CD.
(2) and (3) are similar - they are kept in git repository (often it is an independent service e.g. GitHub) and all you to do is to upload them also inside CI/CD pipeline.
The last part (4) is more problematic, but it concerns only a small part of most workloads. Since all previous parts are in-place, you need to take care of raw data and there are plenty of methods you can use to synchronize data between different clusters (i.e. rsync, block-level snapshots). There aren’t ready solutions to that problem yet, but I believe they will come up either from community or as enterprise, commercial products.
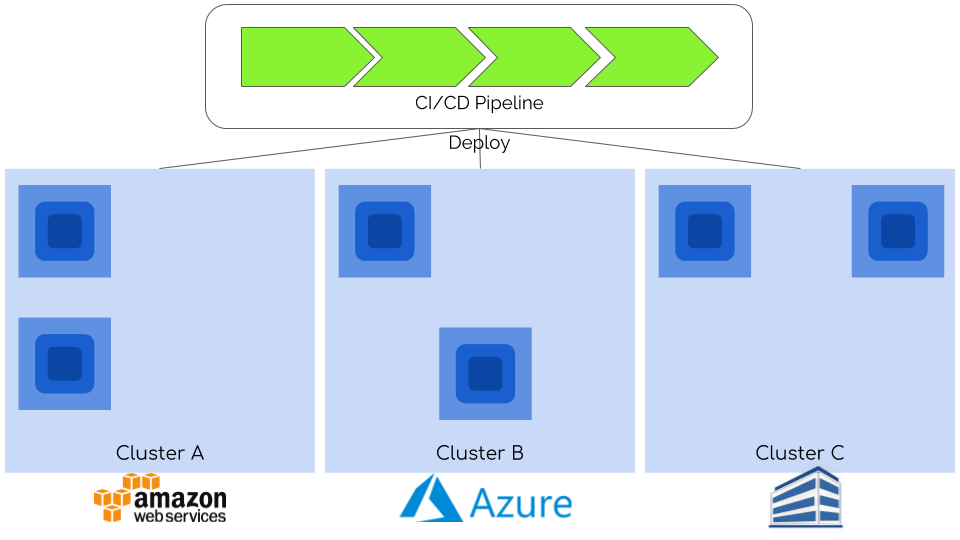
You can create multiple clusters in the cloud using one or many providers. When using single provider you can leverage its services to mitigate data migration issues - for example by using Database-as-a-Service for databases with additional geo-replication options, copying snapshots of underlying PersistentVolumes between regions and many more. For multi-cloud or hybrid solutions you can gain not only higher level of availability, but also more freedom and independency. This latter byproduct is often a Holy Grail for those looking for a real escape from vendor lock-in.
This last level is the most exciting, opening a lot of possibilities, but also the most challenging.
How to increase availability on a cluster level
To fully leverage availability features on this highest level you need to prepare your environment in many areas. Here are the most significant and relevant ones:
-
Data - that’s the biggest challenge here and you should focus on finding a solution to that. For your stateful applicarions you should consider using technology that provides solid replication. You may want to check Rook, as it provides a fully automated (or Cloud Native) way for deploying storage nodes inside Kubernetes cluster. For components like container registries you should find a service that have built-in replication already - I recommend checking Harbor.
-
Design your CI/CD accordingly. It should orchestrate deployments to all clusters using the same container images. You can use any CI/CD orchestrator and I can recommend Jenkins with its huge amount of plugins to all kinds of cloud providers or actually any software that exists today. Use pipelines as code and for big projects I highly advise using shared libraries - it’s the best combination so far despite having some drawbacks (e.g. lack of good testing tools for pipeline code, somewhat painful development process).
-
Control end-user traffic to your clusters with DNS. That’s the easies way and you should pick a right solutions. In worst case you can stick with static dnd entries and in case of failure or maintenance you could change it manually. For bigger and better solution use more sophisticated dns services such as Route53 or similar. They have health checks and complex routing engines that you may find handy.
Summary
Let’s be clear here - you can’t reach 100% level of availability - no one can, even Google (see their error budget approach). Nevertheless, if you wish to improve your level of service, containers running on Kubernetes is currently the best way to achieve it. Improve resilience with the same, common approach regardless of technology you chose to create them, and do it as easy as never before.
Good luck and may your service never crash!




Leave a comment